
Elasticsearch로 빅데이터 다뤄보기 01.개념정리
2019, Jul 21
개념정리.
개념정리 전, 나는 데이터 과학이 발전하면서 함께 공부해 볼 수 있는 기술이 뭐가있을까? 궁금했다.
데이터를 다루는 방법은 저장, 정제, 시각화, 분석 등 다양하게 있지만 어떻게 시작하고 접근해야…하며 찾아보았다.
엘라스틱서치는 정형, 비정형, 위치정보, 메트릭 등 원하는 방법으로 검색을 수행하고 결합가능하다. 처음으로 엘라스틱서치를 선택한 궁극적인 이유는…
확장성과 쉬운 설치다. 데이터를 수집하며, 시각화 기술도 지원하고, 로그 수집하여 정제 분석을 할 수 있으며, 오픈소스 기술이라는 점이 매력적이었다.
또한 분산형 RESTful 검색 및 분석 엔진인 Elastic Search와 오픈소스 서버측 데이터 처리 파이프 라인으로 Stash 보관소로 보내는 역할을 하는 Logstash 그리고 데이터를 시각적으로 탐색하고 실시간으로 분석 가능한 Kibana.
세가지의 오픈소스를 이용해 어떤 운영체제를 만나도 운영 가능하도록, ELK 스택을 마스터한다면, 빅데이터를 만나도 쉽게 관련 개발을 할 수 있다는 점이 하나하나 알아보고 싶은 계기가 되었다.
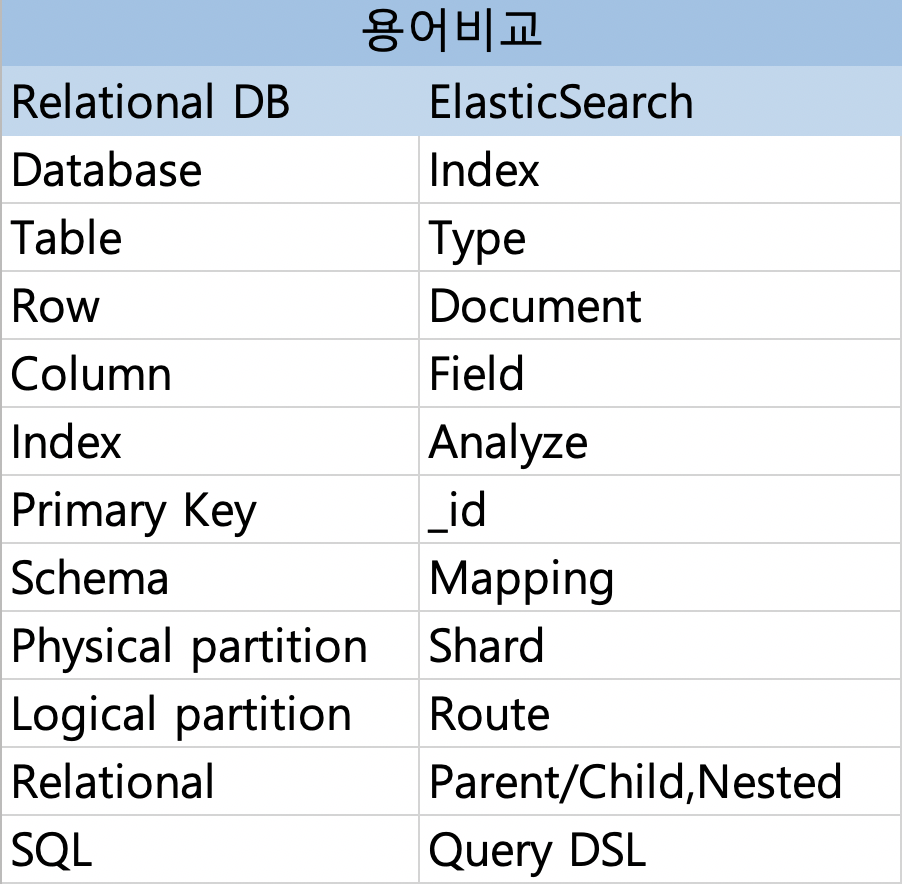
ElasticSearch 와 관계형 DB 용어 비교.
클러스터
- ElasticSearch에서 가장 큰 시스템 단위, 최소 하나 이상의 노드로 이루어진 노드들의 집합.
- 클러스터끼리는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지.
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재 할 수도 있다.
노드
- Elasticsearch를 구성하는 하나의 단위 프로세스를 의미.
-
Master - eligible, Data, Ingest, Trible 노드로 구분할 수 있다.
- Master - eligible node : 클러스터를 제어하는 마스터로 선택 할 수 있는 노드.(인덱스 생성, 삭제,클러스터 노드 추적 관리)
- Data node : CRUD 작업과 관련있는 노드.(메모리 많이 소모, 마스터 노드와 분리하는 것이 좋다.)
- Ingest node: 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할.
- Coordination only node : 데이터 노드와 Master - eligible 노드의 일을 대신하는 역할(로드밸런서 역할)
Index , Shard , Replica
- Elasticsearch에서 index는 RDBMS에서 index와 대응하는 개념.
- sharding은 데이터를 분산해서 저장하는 방법을 의미.
- replica는 또 다른 형태의 shard. 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드들을 복제(replica는 서로 다른 노드에 존재하는 것을 권장)
Restful
- SELECT = GET
- INSERT = PUT
- UPDATE = HEAD
- DELETE = DELETE